UHH>Informatik>NatS>CDG Web>InternalPages>CorpusSurvey>NegraCorpus (17 Oct 2012, UnknownUser) Print version
NEGRA
Description
The German ``NEGRA Corpus'', consists of parsed newspaper texts. See also TigerCorpus.Contact
- Reply from: Thorsten Brants
- EMail: brants@parc.xerox.com
- URL: http://www.coli.uni-sb.de/sfb378/negra-corpus/negra-corpus.html
Documentation
- [SkutEtal97]
-
Wojciech Skut, Thorsten Brants, Brigitte Krenn, and Hans Uszkoreit.
Annotating unrestricted german text.
In Proceedings of the 6th Fachtagung der Sektion
Computerlinguistik der Deutschen Gesellschaft f
"ur Sprachwissenschaft, Heidelberg, Germany, 1997.
- Thorsten Brants (1997): The Negra Export Format for Annotated Corpora (Version 3) Universität des Saarlandes, Computerlinguistik. (PS)
- Hans Uszkoreit et al. (1997): An annotation scheme for free word order languages (PS)
Errors
While converting the corpus into dependency form we frequently encounter errors in the semiautomatic annotations. While many details of description are necessarily different between any two modellers of German, there are also inconsistencies that are clearly errors even by the NEGRA corpus's own guidelines. When such definite errors are found, we correct them and store the result in a private copy of the corpus. Note that we may or may not use the corrected version to actually do experiments on. If we do find previous parsing results for the corpus, a comparison can only be made when we use the same data. On the other hand, for refining our phrase-to-dependency translator the version with fewer errors is preferable. By maintaining our changes in a separate directory we retain the possibility to use either version at any time. So far we have only corrected POS tags that are definitely wrong. Consider the following example: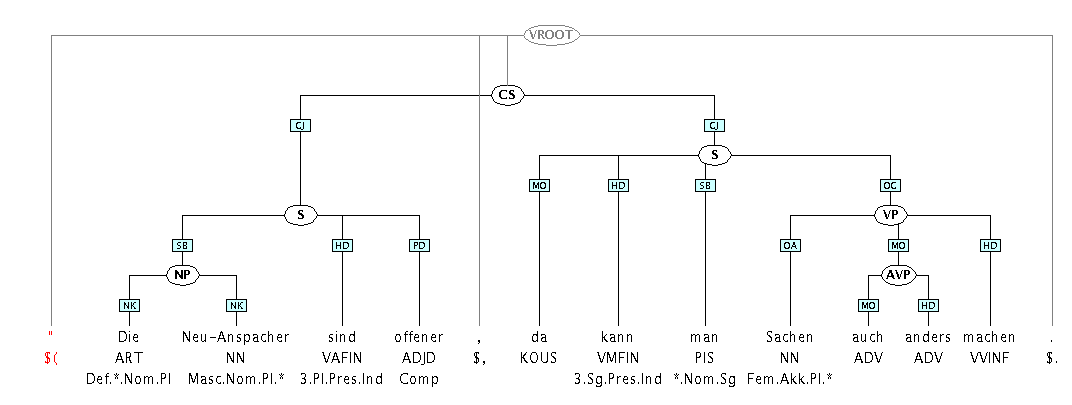 Here, word order clearly proves that we have two main clauses, and
therefore the word "da" is an adverb. But the comma fooled the tagger
into thinking that "da" was a conjunction, and the annotator didn't
catch the error. Therefore we change
Here, word order clearly proves that we have two main clauses, and
therefore the word "da" is an adverb. But the comma fooled the tagger
into thinking that "da" was a conjunction, and the annotator didn't
catch the error. Therefore we change KOUS to ADV.
To see a list of corrected errors, issue the command
(cd /data/corpus/negra/2.0 && diff negra-corpus.export ../2.0-nats)see also: NegraCorpusEdges, NegraCorpusNodes, NegraGrammar, SttsStellingenMapping
- Navigation
|
|
Ideas, requests, problems regarding Foswiki? Send feedback